Question 1 (a): What is a prototyping model? When is it most appropriate to use the prototyping model?
A prototyping model is a software development approach that involves creating a working model or prototype of a system to gather feedback and refine requirements before developing the final product. It allows stakeholders to visualize and interact with an early representation of the system, providing valuable insights for improvement.
The prototyping model is most appropriate to use in the following situations:
- Requirement Uncertainty: When the requirements are not well-defined or are subject to change, prototyping helps clarify and solidify them. Stakeholders can provide feedback on the prototype, leading to a better understanding of their needs and refining the requirements accordingly.
- User-Centric Design: When the user experience and interface design are critical, prototyping enables designers and developers to gather user feedback early in the process. This helps create a user-friendly and intuitive final product that meets user expectations.
- Risk Mitigation: When there are technical or project risks, prototyping allows for early identification and mitigation. By developing a prototype, potential issues can be identified and resolved before investing significant time and resources in the full-scale development.
- Complex Systems: When dealing with complex systems or technologies, prototyping helps in exploring feasibility, performance, and integration challenges. It allows developers to experiment with different approaches and make informed decisions based on the prototype’s outcomes.
- Time and Cost Constraints: When there are time or budget limitations, prototyping can help prioritize features and functionalities. By focusing on key aspects and validating them through prototypes, it becomes possible to deliver a minimum viable product within the given constraints.
Question 1 (b): What is a Gantt chart? How is it used for project scheduling?
A Gantt chart is a visual representation of a project schedule that illustrates the timeline of tasks, their durations, and their dependencies. It provides a graphical view of project activities, helping project managers and teams plan, schedule, and track progress effectively.
Gantt charts are used for project scheduling in several ways:
- Planning and Scheduling: Gantt charts provide a visual overview of project tasks, their durations, and their dependencies. They help project managers allocate resources, identify critical paths, and establish realistic timelines for completing tasks.
- Task Dependencies: Gantt charts allow project managers to define task dependencies and understand how changes in one task’s schedule can impact others. By visualizing dependencies, teams can ensure that tasks are sequenced appropriately and avoid delays or bottlenecks.
- Progress Tracking: Gantt charts enable tracking the progress of tasks throughout the project lifecycle. As tasks are completed, their corresponding bars are updated, providing a clear indication of completed, ongoing, and pending activities. This helps stakeholders monitor project status and identify potential delays or issues.
- Resource Management: Gantt charts help project managers allocate and manage resources effectively. By visualizing task durations and resource availability, teams can identify resource conflicts and adjust schedules accordingly. This facilitates optimal resource utilization and prevents overloading or underutilization.
- Communication and Collaboration: Gantt charts serve as a communication tool to share project schedules with team members, stakeholders, and clients. They provide a clear and concise representation of the project plan, fostering collaboration, and ensuring everyone involved has a shared understanding of timelines and deliverables.
Question 1 (c): What is an SRS? List any 3 characteristics of SRS.
SRS stands for Software Requirements Specification. It is a document that describes the functional and non-functional requirements of a software system. The SRS serves as a reference for stakeholders, including developers, testers, and clients, to understand and agree upon the software requirements.
Here are three characteristics of an SRS:
- Comprehensive
- Clear and Unambiguous
- Traceable and Verifiable
Question 1 (d): State three basic assumptions which an agile process is expected to handle.
Agile processes are designed to handle certain basic assumptions in software development. Here are three common assumptions that an agile process is expected to address:
- Requirements Volatility: Agile processes assume that requirements will change and evolve throughout the project lifecycle. Instead of trying to define all requirements upfront, agile methodologies emphasize iterative and incremental development, allowing for flexibility and adaptability. The process accommodates changing requirements by enabling frequent collaboration and feedback from stakeholders, ensuring that the software meets their evolving needs.
- Uncertainty and Complexity: Agile processes recognize that software development is often complex and uncertain. They embrace the fact that not all requirements and challenges can be predicted at the beginning of a project. Agile methodologies provide a framework for managing complexity by breaking down the work into smaller, manageable increments or iterations. This approach enables teams to address uncertainties incrementally, learn from feedback, and make necessary adjustments throughout the development process.
- Stakeholder Collaboration and Engagement: Agile processes assume that stakeholders, including customers, end-users, and development team members, need to collaborate closely throughout the project. Agile methodologies emphasize regular communication, feedback loops, and frequent demonstrations of working software to keep stakeholders engaged and ensure their ongoing involvement. By fostering collaboration, agile processes enable the development team to gain a deep understanding of stakeholders’ needs, gather valuable input, and deliver a product that aligns with their expectations.
Question 1 (e): What is risk exposure? How is Risk Exposure determined?
Risk exposure refers to the potential financial loss or negative impact that an organization may experience due to a risk event or uncertain circumstances. It represents the amount at stake if a risk were to materialize and adversely affect the organization’s objectives or projects.
Here’s a general process for determining risk exposure:
- Identify Risks: The first step is to identify and document the potential risks that could affect the organization or a specific project. This can be done through risk identification techniques such as brainstorming sessions, risk registers, historical data analysis, or expert judgment.
- Assess Probability: Once the risks are identified, their probability or likelihood of occurring needs to be assessed. This involves analyzing historical data, expert opinions, statistical models, or other relevant sources of information to estimate the chances of each risk event happening. Probability can be expressed as a percentage or a qualitative assessment (e.g., high, medium, low).
- Evaluate Impact: Next, the potential impact of each risk event needs to be evaluated. Impact can be assessed in various dimensions, such as financial, operational, reputational, or strategic. The impact assessment considers the magnitude of the consequences and the duration or persistence of those consequences. The impact can be expressed quantitatively (e.g., monetary value) or qualitatively (e.g., high, medium, low).
- Calculate Risk Exposure: Risk exposure is determined by multiplying the probability of a risk event by its estimated impact. This calculation provides a quantitative measure of the potential financial loss or negative impact associated with each risk. The formula for calculating risk exposure is:Risk Exposure = Probability of the Risk Event × Estimated Impact
- Prioritize and Mitigate: Once the risk exposure is determined for each identified risk, organizations can prioritize them based on their level of exposure. Risks with higher exposure may require more attention and mitigation efforts. The organization can then develop risk mitigation strategies, such as risk avoidance, risk transfer, risk reduction, or risk acceptance, to address the identified risks and reduce their exposure.
Question 1 (f): What do you understand by CMMI? Explain the various levels of CMMI.
CMMI stands for Capability Maturity Model Integration. It is a framework that helps organizations improve their processes and practices in order to achieve higher levels of maturity and capability in delivering quality products and services. CMMI provides a set of best practices and guidelines that organizations can follow to enhance their performance, manage risks, and ensure customer satisfaction.
CMMI has five levels, each representing a different degree of process maturity and capability. These levels are:
- Level 1 – Initial: At this level, the organization’s processes are typically ad hoc, chaotic, and unpredictable. There is little or no process discipline, and success depends heavily on individual effort and heroics. The focus is on delivering results, but the processes are not well defined or repeatable.
- Level 2 – Managed: At this level, the organization begins to establish basic project management controls and processes. Project work is planned, tracked, and monitored, and there is a focus on requirements management, project planning, and project tracking. The processes are documented, standardized, and repeatable, providing a foundation for consistency and control.
- Level 3 – Defined: At this level, the organization establishes a set of defined and standardized processes across projects and departments. There is a focus on process standardization, process documentation, and process improvement. The organization has a defined process framework and guidelines, and there is an emphasis on proactive risk management and process optimization.
- Level 4 – Quantitatively Managed: At this level, the organization focuses on quantitative management and measurement of its processes. It establishes quantitative objectives for process performance and uses data and statistical techniques to manage and control process performance. The organization collects and analyzes process performance data to make informed decisions and continuously improve its processes.
- Level 5 – Optimizing: At the highest level of maturity, the organization focuses on continuous process improvement. It proactively identifies opportunities for innovation, process optimization, and performance improvement. The organization fosters a culture of innovation, encourages experimentation, and implements best practices to achieve higher levels of quality, efficiency, and customer satisfaction.
Question 1 (g): “Software Engineering is a layered technology”. Justify the given statement.
Here’s a justification for the statement:
- Requirement Layer: The first layer in software engineering is the requirement layer, where the focus is on understanding and capturing the needs and expectations of the software system’s stakeholders. Requirements engineering involves activities such as gathering, analyzing, documenting, and validating requirements. This layer establishes the foundation for the software development process.
- Design Layer: The design layer involves transforming the requirements into a well-structured design that specifies the software system’s architecture, components, and interfaces. It encompasses activities such as architectural design, module design, data design, and user interface design. The design layer provides a blueprint for the implementation phase.
- Implementation Layer: The implementation layer involves translating the design into executable code. This layer includes activities such as coding, unit testing, and integration testing. It focuses on writing efficient, maintainable, and bug-free code that realizes the design specifications.
- Testing Layer: The testing layer is responsible for verifying and validating the software system’s behavior and performance. It includes activities such as system testing, acceptance testing, and performance testing. This layer ensures that the software meets the specified requirements and performs as expected.
- Deployment Layer: The deployment layer involves activities related to delivering the software system to the end-users or customers. It includes tasks such as installation, configuration, and user training. This layer ensures that the software is successfully deployed and ready for use in the intended environment.
- Maintenance Layer: The maintenance layer focuses on enhancing and maintaining the software system throughout its lifecycle. It involves activities such as bug fixing, adding new features, and addressing user feedback. This layer ensures that the software remains reliable, secure, and up-to-date.
Question 1 (h): Explain any two development activities defined by the process patterns used in Scrum.
Two key development activities in Scrum are Sprint Planning and Daily Stand-up Meetings:
- Sprint Planning: Sprint Planning is a collaborative activity that occurs at the beginning of each sprint, which is a time-boxed iteration in Scrum. During this activity, the Scrum Team, including the Product Owner, Scrum Master, and Development Team, come together to plan and prioritize the work to be undertaken in the upcoming sprint. The main objectives of Sprint Planning include:
a) Product Backlog Refinement: The Product Owner presents the items from the Product Backlog that are of highest priority and discusses them with the Development Team. The team analyzes and discusses the requirements, seeking clarification if needed, and identifies any additional work needed to be done to make the backlog items ready for implementation.
b) Sprint Goal Definition: The team collaboratively defines the Sprint Goal, which is a short and concise description of what the team intends to achieve during the sprint. The Sprint Goal serves as a guiding principle and helps the team make decisions about which backlog items to include in the sprint.
c) Task Estimation and Commitment: The Development Team breaks down the selected backlog items into smaller, manageable tasks and estimates the effort required to complete each task. Based on these estimations, the team determines the amount of work they can commit to delivering during the sprint, considering their capacity and velocity. - Daily Stand-up Meetings: Daily Stand-up Meetings, also known as Daily Scrums, are brief, time-boxed meetings held by the Development Team every day during a sprint. The purpose of these meetings is to synchronize and collaborate on the progress of work and address any impediments. Key aspects of Daily Stand-up Meetings include:
a) Progress Reporting: Each team member provides a brief update on the work they completed since the last meeting, what they plan to accomplish by the next meeting, and any obstacles or challenges they are facing. The focus is on sharing information about the progress of work and ensuring transparency within the team.
b) Coordination and Alignment: The Daily Stand-up Meeting provides an opportunity for team members to coordinate their efforts, identify dependencies, and align their work. It helps in identifying potential bottlenecks or conflicts and promotes collaboration and self-organization within the team.
c) Problem-solving and Impediment Removal: If any team member faces obstacles or impediments that are affecting their progress or the team’s overall productivity, the Daily Stand-up Meeting serves as a platform to raise those issues. The team can discuss potential solutions, seek help from other team members or the Scrum Master, and make plans to address the impediments.
Question 1 (i): What is Cohesion? Explain any three different types of cohesion.
Cohesion in software engineering refers to the degree of interdependence and logical unity among the components or modules within a software system. It measures how closely the elements within a module are related to each other in terms of functionality and purpose. Higher cohesion indicates stronger logical unity and a clearer focus on a specific task or responsibility within a module. Here are three different types of cohesion:
- Functional Cohesion: Functional cohesion occurs when the elements within a module are related and contribute to a single well-defined function or task. In this type of cohesion, all the components within a module work together to achieve a common objective or perform a specific operation. The focus is on grouping related functions or operations together within the same module. Examples of functional cohesion include modules that handle file input/output, perform mathematical calculations, or manage user authentication.
- Sequential Cohesion: Sequential cohesion exists when the elements within a module are arranged in a specific order, and the output of one component becomes the input for the next component in a sequence. The components within the module are dependent on each other in a sequential manner. This type of cohesion is often found in modules that implement a step-by-step process or workflow. For example, a module for processing an online purchase may have components for adding items to a shopping cart, selecting a shipping method, and processing payment in a specific sequence.
- Communicational Cohesion: Communicational cohesion occurs when the elements within a module operate on the same data or share common input/output. The components within the module are focused on a common set of data or information. This type of cohesion is typically seen in modules that perform operations on a shared data structure or communicate with the same external entities. For instance, a module that handles database operations, where different components interact with the same database tables or entities, exhibits communicational cohesion.
Question 2: Explain the following terms:
(i) Known requirements
(ii) Unknown requirements
(iii) Undreamt requirements
(iv) Functional requirements
(v) Non-functional requirements
- Known requirements: Known requirements refer to the set of requirements that are identified, documented, and understood by the project stakeholders at a particular point in time. These requirements are typically captured through various techniques such as interviews, workshops, and documentation analysis. Known requirements are explicit and can be used as a basis for planning, designing, and developing a software system.
- Unknown requirements: Unknown requirements are those that are not fully understood or identified at the beginning of a project or software development process. These requirements may emerge during the course of the project as stakeholders gain more insights or as the project progresses. Unknown requirements represent the need for flexibility and adaptability in software development, as they require teams to be prepared to handle changing requirements and incorporate new features or functionalities.
- Undreamt requirements: Undreamt requirements refer to the needs or desires of stakeholders that were not envisioned or anticipated by anyone involved in the project. These requirements arise when stakeholders come up with new ideas or concepts that were not previously considered or discussed. Undreamt requirements can emerge through ongoing collaboration, feedback, or new insights gained during the development process. Handling undreamt requirements requires an agile and iterative approach, allowing for continuous adaptation and innovation.
- Functional requirements: Functional requirements define the specific behaviors, features, and functionalities that a software system should exhibit to meet the needs of its users. These requirements describe the system’s intended operations, input data, processing logic, and expected outputs. Functional requirements typically answer questions such as “What should the software do?” or “How should the software respond to specific inputs?” Examples of functional requirements include user authentication, data validation, report generation, or integration with external systems.
- Non-functional requirements: Non-functional requirements specify the qualities, characteristics, and constraints that a software system should possess, beyond its functional behavior. These requirements define the system’s performance, usability, security, reliability, scalability, and other attributes that contribute to its overall quality. Non-functional requirements often focus on aspects such as response time, availability, maintainability, accessibility, and regulatory compliance. They address questions related to “How well should the software perform?” or “What are the quality attributes that the software should exhibit?” Non-functional requirements help shape the overall user experience and ensure that the software system meets specific quality standards.
Question 3: The given system computes the salary of the employees and generates the salary slip. Create context level and level 1 DFD (Data Flow Diagram) of the given system. Also, draw the data dictionary of the system.
(i) The basic input is the weekly timesheet
(ii) The source for the input is a workerThe basic output is the pay-checkThe sink for the output is also a worker
Procedure:
(i) In this system, first, the employee’s record is retrieved, using the employee ID, which is contained in the timesheet.
(ii) From the employee record, the rate of payment and overtime are obtained.
(iii) These rates and the regular and overtime hours are used to compute the pay.
(iv) After the total pay is determined, taxes are deducted.
(v) To compute the tax deduction, information from the tax rate file is used.
(vi) The amount of tax deducted is recorded in the employee and company records.
(vii) Finally, the paycheck is issued for the net pay.
(viii)The amount paid is also recorded in the company records.
Context Level DFD: The context level DFD provides an overview of the system and shows its interactions with external entities. In this case, the system interacts with the worker who provides the weekly timesheet and receives the pay-check.
Worker
|
+-------+-------+
| |
| Salary System |
| |
+-------+-------+
|
WorkerLevel 1 DFD: The level 1 DFD delves into more detail, expanding the processes within the system and showing the data flows between them.
Worker
|
+-------+-------+
| |
| Salary System |
| |
+-------+-------+
|
+----------+---------+
| |
| Retrieve Record |
| |
+----------+---------+
|
+-------+-------+
| |
| Employee |
| Record |
| |
+-------+-------+
|
+----------+---------+
| |
| Retrieve Rates |
| |
+----------+---------+
|
+-------+-------+
| |
| Rate |
| Information |
| |
+-------+-------+
|
+----------+---------+
| |
| Compute Pay |
| |
+----------+---------+
|
+-------+-------+
| |
| Pay |
| Information |
| |
+-------+-------+
|
+----------+---------+
| |
| Deduct Taxes |
| |
+----------+---------+
|
+-------+-------+
| |
| Tax Rate |
| Information |
| |
+-------+-------+
|
+----------+---------+
| |
| Record Taxes |
| |
+----------+---------+
|
+-------+-------+
| |
| Employee and |
| Company |
| Records |
| |
+-------+-------+
|
WorkerData Dictionary: Here’s a data dictionary that describes the data elements used in the system:
Entity: Worker
Attributes: Worker ID
Entity: Employee Record
Attributes: Employee ID, Rate of Payment, Overtime
Entity: Rate Information
Attributes: Regular Hours, Overtime Hours
Entity: Pay Information
Attributes: Total Pay
Entity: Tax Rate Information
Attributes: Tax Rate
Entity: Employee and Company Records
Attributes: Tax Deduction, Net Pay, Amount Paid
Process: Retrieve Record
Inputs: Worker ID
Outputs: Employee Record
Process: Retrieve Rates
Inputs: Employee ID
Outputs: Rate Information
Process: Compute Pay
Inputs: Regular Hours, Overtime Hours, Rate of Payment, Overtime
Outputs: Pay Information
Process: Deduct Taxes
Inputs: Pay Information, Tax Rate
Outputs: Tax Deduction
Process: Record Taxes
Inputs: Tax Deduction
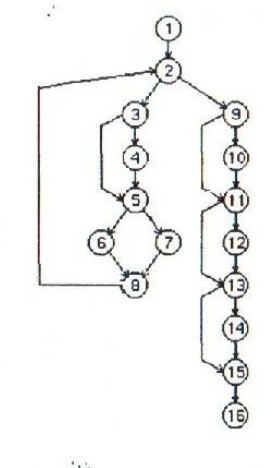
Outputs: Employee and Company RecordsQuestion 4: Compute the Cyclomatic Complexity of the given flow graph using three different methods. Identify all the regions and list all the independent paths of the flow graph:
Question 5 (a): How are maintainability and integrity of the software used as a measure of software quality?
- Maintainability: Maintainability refers to the ease with which software can be modified, enhanced, and repaired over its lifecycle. It measures how well the software system supports future changes and updates. High maintainability indicates that the software is designed and implemented in a way that allows developers to understand, modify, and extend it without introducing errors or unintended side effects. Maintaining software becomes easier when it has clear and modular code structure, well-documented components, and follows established coding standards. Improving maintainability helps reduce the cost and effort required for software maintenance, and ensures that changes can be made quickly and effectively without compromising the system’s integrity.
- Integrity: Integrity, in the context of software quality, refers to the accuracy, reliability, and consistency of the software system and its data. It ensures that the software behaves as intended, produces correct results, and safeguards against unauthorized or unintended modifications or access. Software integrity is crucial for applications that handle sensitive data, perform critical operations, or have strict regulatory requirements. To ensure integrity, software should have robust input validation mechanisms, error handling routines, and security measures to prevent unauthorized access or tampering. Additionally, thorough testing, including functional and non-functional testing, helps identify and address integrity issues early in the software development lifecycle. Maintaining integrity is essential for building trust in the software and ensuring its reliable operation.
Question 5 (b): Explain the following metric to determine the specification quality:
(i) Specificity
(ii) Completeness of the functional requirement
- Specificity: Specificity refers to the level of detail and precision in the specification of requirements. A specific requirement is one that leaves no room for ambiguity or multiple interpretations. It provides clear and unambiguous instructions, leaving little room for misunderstanding. High specificity in requirements ensures that developers have a clear understanding of what needs to be implemented and reduces the risk of miscommunication or misinterpretation. It helps in preventing errors, rework, and misunderstandings during the development process. The more specific the requirements, the easier it is to validate and verify the implemented software against those requirements.
- Completeness of the Functional Requirement: Completeness of the functional requirement measures the extent to which all necessary functionalities of the software system are adequately captured and described in the requirements specification. It ensures that all essential features, operations, and behaviors that the software is expected to exhibit are explicitly defined. A complete functional requirement specifies all relevant inputs, expected outputs, processing logic, and any constraints or conditions that need to be satisfied. Incomplete requirements may result in missing or overlooked functionalities, leading to gaps in the software’s intended behavior. By ensuring completeness, the development team can have a comprehensive understanding of the required functionalities, and stakeholders can have confidence that the software will meet their needs.
Question 6 (a): Compute the Functional Point value for a project with the following information domain characteristics:
Assume the measurement parameter are equally divided among low, average, and high complexity. Further, assume that the complexity adjustment value is 1.05.
| Measurement Parameters | count | Weighting Factors | ||
| Low | Average | High | ||
| Number of user inputs | 12 | 3 | 4 | 6 |
| Number of user outputs | 21 | 4 | 5 | 7 |
| Number of user inquiries | 6 | 3 | 4 | 6 |
| Number of files | 6 | 7 | 10 | 15 |
| Number of external interfaces | 9 | 5 | 7 | 10 |
To compute the Functional Point value for the project based on the given information, we need to follow the steps of the Function Point Analysis method:
Step 1: Determine Complexity Value
We will assign complexity values to each measurement parameter based on their level (low, average, high) and the given weighting factors:
Number of user inputs:
Low complexity = 12 x 3 = 36
Average complexity = 12 x 4 = 48
High complexity = 12 x 6 = 72
Number of user outputs:
Low complexity = 21 x 4 = 84
Average complexity = 21 x 5 = 105
High complexity = 21 x 7 = 147
Number of user inquiries:
Low complexity = 6 x 3 = 18
Average complexity = 6 x 4 = 24
High complexity = 6 x 6 = 36
Number of files:
Low complexity = 6 x 7 = 42
Average complexity = 6 x 10 = 60
High complexity = 6 x 15 = 90
Number of external interfaces:
Low complexity = 9 x 5 = 45
Average complexity = 9 x 7 = 63
High complexity = 9 x 10 = 90
Step 2: Calculate Total Unadjusted Function Points (UFP)
We sum up the complexity values of all the measurement parameters:
Total UFP = (36 + 48 + 72) + (84 + 105 + 147) + (18 + 24 + 36) + (42 + 60 + 90) + (45 + 63 + 90)
= 156 + 336 + 78 + 192 + 198
= 960
Step 3: Apply Complexity Adjustment Factor
We multiply the total UFP by the complexity adjustment value:
Adjusted Function Points (AFP) = Total UFP x Complexity Adjustment Value
= 960 x 1.05
= 1,008
The Functional Point value for the project, based on the given information, is 1,008.
Question 6 (b): At the conclusion of the project, it has been determined that 30 errors were found during the modeling activity and 12 errors were found during the construction activity that were traceable to errors that were not discovered in the modeling activity. What is the DRE for the modeling activity?
To calculate the Defect Removal Efficiency (DRE) for the modeling activity, we need to determine the ratio of errors found during the modeling activity to the total number of errors.
Total Errors = Errors found during modeling activity + Errors found during construction activity
= 30 + 12
= 42
DRE = (Errors found during modeling activity / Total Errors) x 100
= (30 / 42) x 100
= 0.714 x 100
= 71.4%
Therefore, the Defect Removal Efficiency (DRE) for the modeling activity is 71.4%.
Question 7 (a): Draw a use case diagram for an online shopping portal “ESHOP”, the functional requirements are as given below:
(i) The users will log in and the admin will authenticate the login details of the user.
(ii)After successful login users can select the product to purchase and keep them in the cart.
(iii) They can view and edit the cart items.
(iv) To place the order user has to calculate the total amount to be paid which is verified by the admin.
(v) After verification, the payment can be done through a credit card.
(vi) The payment receipt is sent by mail to the user.
+---------+ +---------+
| User | | Admin |
+---------+ +---------+
| |
|---------> Login <-------|
| |
|--------> Select Product <-------|
| |
|------> View/Edit Cart <------|
| |
|--> Calculate Total Amount -->|
| |
|---> Make Payment --->|
| |
|-> Receive Payment Receipt ->|Question 7 (b): Consider a program for computing the function f(x, y), where the input boundaries of x and y are given below:
1 ≤ x ≤ 10
10 ≤ y ≤ 20.
Design the boundary value test cases for the above program.
To design boundary value test cases for the program computing the function f(x, y) with the given input boundaries of x and y (1 ≤ x ≤ 10, 10 ≤ y ≤ 20), we consider the following test cases:
- Minimum x and minimum y:
- Test case 1: x = 1, y = 10
- Test case 2: x = 1, y = 11
- Minimum x and maximum y:
- Test case 3: x = 1, y = 20
- Test case 4: x = 1, y = 19
- Maximum x and minimum y:
- Test case 5: x = 10, y = 10
- Test case 6: x = 10, y = 11
- Maximum x and maximum y:
- Test case 7: x = 10, y = 20
- Test case 8: x = 10, y = 19
- On-boundary x and minimum y:
- Test case 9: x = 5, y = 10
- Test case 10: x = 6, y = 10
- On-boundary x and maximum y:
- Test case 11: x = 5, y = 20
- Test case 12: x = 6, y = 20
- Minimum x and off-boundary y:
- Test case 13: x = 1, y = 21
- Test case 14: x = 1, y = 19
- Maximum x and off-boundary y:
- Test case 15: x = 10, y = 21
- Test case 16: x = 10, y = 19
- Off-boundary x and minimum y:
- Test case 17: x = 0, y = 10
- Test case 18: x = 11, y = 10
- Off-boundary x and maximum y:
- Test case 19: x = 0, y = 20
- Test case 20: x = 11, y = 20
Question 8 (a): What is the top-down and bottom approach for integration testing? Explain the use of Stubs and Drivers in the context of Integration Testing. Illustrate with an example.
Top-Down Approach: In the top-down approach, testing begins with the higher-level modules or components and gradually progresses to the lower-level modules. It follows a step-by-step process where the main control module is tested first, and then the modules that are called by the main control module are integrated and tested next. The lower-level modules are simulated or replaced by stubs to imitate their behavior.
Bottom-Up Approach: In the bottom-up approach, testing begins with the lower-level modules or components and gradually integrates the higher-level modules. It starts with testing individual components, then groups of components, and finally integrates them into larger subsystems or the main system.
Use of Stubs: Stubs are temporary implementations of lower-level modules or components that simulate their functionality and return predefined values. Stubs are utilized in top-down integration testing to replace the lower-level modules that have not been developed or integrated yet. They allow testing of the higher-level modules in isolation, enabling the detection of issues related to control flow, data flow, and interface compatibility.
Use of Drivers: In the bottom-up approach, drivers are used to simulate the higher-level modules or components that call the lower-level modules being tested. A driver is a test component that replaces the higher-level modules and provides test inputs to the lower-level modules. It allows for the testing of the lower-level modules’ functionality and interaction without having the higher-level modules fully developed or integrated.
Question 8 (b): Explain any FOUR key quality attributes as identified by ISO 9126 standards.
Four key quality attributes identified by ISO 9126 standards are as follows:
- Functionality: Functionality refers to the extent to which software meets specified functional requirements. It includes features, capabilities, and suitability for specific tasks. Key aspects of functionality include correctness, completeness, interoperability, and compliance with standards. A software product should perform its intended functions accurately and efficiently.
- Reliability: Reliability refers to the ability of software to perform its intended functions consistently and dependably under specified conditions. It includes attributes like availability, fault tolerance, recoverability, and accuracy. Reliability ensures that the software operates correctly, consistently, and without unexpected failures or errors over a specified period.
- Usability: Usability refers to the ease of use and understandability of the software by its intended users. It includes attributes like learnability, operability, user interface design, and user documentation. Usability focuses on making the software user-friendly, intuitive, and efficient, ensuring that users can easily navigate and accomplish their tasks without unnecessary complexities or confusion.
- Maintainability: Maintainability refers to the ease with which software can be modified, adapted, or enhanced. It includes attributes like modularity, reusability, analyzability, and testability. Maintainability ensures that software can be efficiently maintained, updated, and repaired over its lifecycle, reducing the cost and effort required for future modifications or enhancements.